|
Research Interests :
|
|
Research Area :
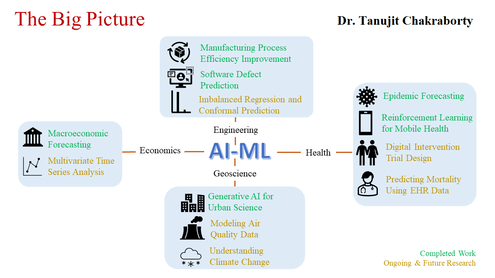
"Statistical Science" is constantly challenged by the problems that Science and Industry bring to its door. Vast amounts of data are being generated in many fields, and the statistician's job is to make sense of it all, which includes extraction of important patterns and trends and understand "what the data says". We call this "learning from data" and this can roughly be summarized in the following steps: (a) observe a phenomenon; (b) construct a model for that phenomenon; (c) make predictions using the model. Broadly speaking, 'Statistical Learning' refers to a set of tools for modeling and understanding complex data sets that blends statistics with parallel developments in machine learning.
I work on "application-driven theory" meaning that the majority of my research papers are designing theoretically principled ML models that directly solve real-life problems. Most of the algorithms we developed are based on simple but aesthetically elegant (in my opinion).
My research works involve developing statistical methodologies for "data-driven problems" from various applied disciplines (e.g., Epidemiology, Biology, Mobile Health, Business, Software Reliability, Quality Engineering, Macroeconomics, Nonlinear Dynamics and Network Analysis). My primary research interest lies in Statistical Machine Learning with a particular emphasis on hybrid representation learning, imbalanced learning, and nonparametric learning. My recent research interests focus on Applied Time Series Forecasting, Health Data Sciences, and Statistical Analysis of Networks. I am trying to contribute in both methodological and application aspects.